Do LLMs recognize Medical Definitions?
 Figure: Do LLMs recognize Medical Definitions?
Figure: Do LLMs recognize Medical Definitions?
There’s been a never-ending debate about whether LLMs understand the data they process, so much so that people have started to debate what understanding something actually means.
While some argue that LLMs are mere statistical machines that capture patterns of when and where different words are used, others claim that LLMs do indeed have a sense for the underlying meanings of words.
One undeniable thing is that LLMs need to remember/store facts to perform well on most tasks. The definitions of words, in my humble opinion, are facts. Knowing the definitions of words lays the foundation for an intelligence to be able to use them correctly in context and perhaps even understand them.
Medicine is a domain where it’s critical to know what different terms mean. Suppose a doctor doesn’t know the difference between a stroke and a heart attack. In that case, you’d be very skeptical about their ability to recognize and diagnose patients suffering from one or the other.
The ability to recognize definitions also helps us understand whether there’s a need for building domain-specific LLMs or augmenting existing LLMs with additional tools, fine-tuning, grounding via rag etc., to acquire domain knowledge.
In this blog, we’ll evaluate different LLMs on their ability to recognize the definitions of medical terms. All code corresponding to this blog can be found here.
Task Description
The prompt used is:
1
2
3
4
5
6
7
8
9
10
11
12
13
You are a word prediction model.You will be given a definition and the part of speech of a medical word/term (if available).You must predict the medical word/term being defined.
Respond with just the word and no additional text.
# Examples:
Definition: A partial or complete break in the continuity of any bone in the body.
Part of speech: noun
Answer: Fracture
Definition: A Y-shaped protein produced by the body's immune system to identify and neutralize foreign substances, called antigens, like bacteria and viruses.
Part of speech: noun
Answer: Antibody
Definition: {definition}
Part of speech: {part_of_speech}
Answer:
Dataset Creation
We leverage the Merriam-Webster Medical Dictionary API to fetch definitions of medical terms.
The api requests require two arguments: ‘word’: The word whose definition is to be fetched ‘api_key’: The api key to authenticate the request
To get a list of medical terms to query the API, we use an open-source repo that scraped medical terms from:
- OpenMedSpel by e-MedTools
- Raj&Co-Med-Spel-Chek by Rajasekharan N. of Raj&Co
The dataset is then processed to get a csv file with the following columns:
- word: The medical term
- definition: The definition of the medical term
- part_of_speech: The part of speech of the medical term
- synonyms: The synonyms of the medical term
The processing and interpretation of the fields returned in the response object of the API are a bit convoluted, and readers interested in learning more can refer to the code.
It’s also important to note that in the context of this dataset, the synonyms map to words/terms that share the same stem of the word rather than true synonyms. An example of synonyms that share the same stem is
1
cataplasia -> 'cataplasias', 'cataplastic'
We take additional steps to make sure that neither the term nor any of its stems occurs in the definition. We also have length filters of >=50 and <=1000 characters on the definitions.
The API has a soft limit of 1000 requests per day, we built a dataset of 1100 examples. The dataset can be found here.
Model Evaluation
We evaluate the models using the following metrics:
- Exact Match: Case insensitvie exact match between the term and the prediction.
- Fuzzy Match: A simple bi-directional
is incheck on the prediction and the medical term. - Synonym Match: Check if the predicted term matches any of the stems.
- JudgeLLM Match: We use a JudgeLLM (GPT-4.1) to evaluate if the prediction and the medical term are synonymous given the definition. This helps us account for synonyms that don’t share the same stem.
It’s important to note that fuzzy, synonym, and judgellm match scores are all supersets of the exact match score. i.e.
1
2
3
fuzzy_accuracy = exact_accuracy + fuzzy_match_score
synonym_accuracy = exact_accuracy + synonym_match_score
judgellm_accuracy = exact_accuracy + judge_llm_match_score
Model Providers
The current code base supports querying OpenAI, Anthropic, Gemini and models hosted on Together.ai using litellm.
We leverage vLLM to run local open source models. All local models were run on an A40 GPU with 44GB of vRAM.
Generation Parameters
We simulate greedy decoding by setting the temperature to 0 and top_p to 0.001. Such a small top_p almost guarantees that the token with the highest logit is always selected at each decoding step.
JudgeLLM Prompt
The prompt used for the JudgeLLM is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
You are an expert linguist. You will judge if two words are the same or synonymous given a definition. Respond with a single word: 'Yes' or 'No'.
## Examples
Definition: Bleeding from the nose, usually due to ruptured blood vessels in the nasal mucosa.
Are the words 'Epistaxis' and 'Nosebleed' the same or synonymous? Yes
Definition: The largest part of the brain, responsible for higher brain functions like thought, action, and sensory processing.
Are the words 'Cerebrum' and 'Forebrain' the same or synonymous? Yes
Definition: An elevated body temperature, often due to infection or illness.
Are the words 'Fever' and 'diarrhea' the same or synonymous? No
Definition: a single-stranded RNA molecule that carries genetic information
and from the DNA in the cell's nucleus to the cytoplasm, where proteins are synthesized
Are the words 'mRNA' and 'Messenger RNA' the same or synonymous? Yes
Definition: beat or sound with a strong, regular rhythm; pulsate steadily.
Are the words 'throb' and 'throbbing' the same or synonymous? Yes
Definition: {definition}
Are the words '{word_1}' and '{word_2}' the same or synonymous?
Results
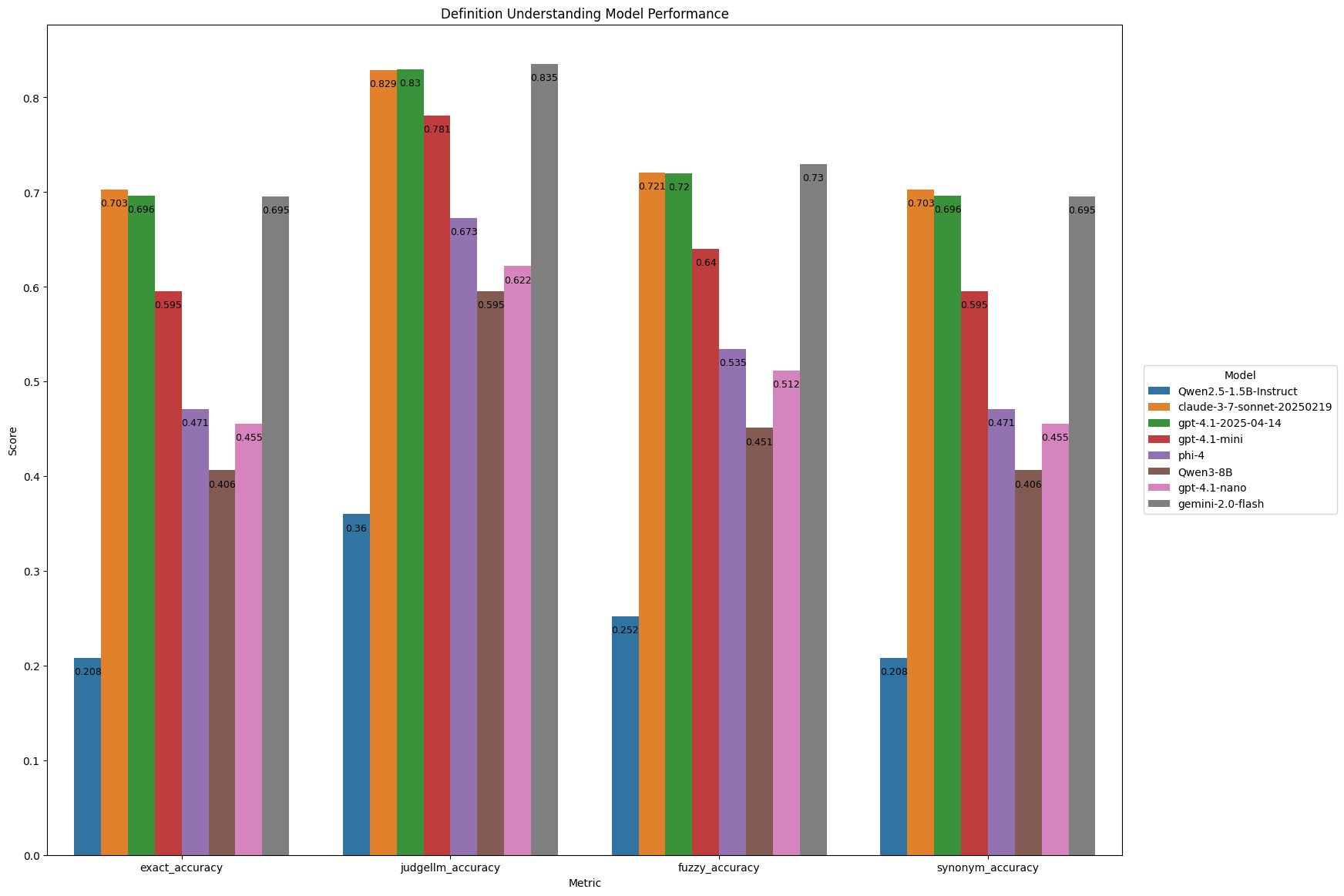 Figure: Performance comparison of evaluated language models on the definition understanding task.
Figure: Performance comparison of evaluated language models on the definition understanding task.
Key Takeaways
- Gemini-2.0-Flash has the best exact and judge llm accuracy, while Claude-3.5-Sonnet has the best synonym and fuzzy accuracy.
- Exact match accuracies do not exceed 0.7, and Judge LLM accuracies do not exceed 0.84.
- GPT-4.1 is very competitive with Claude and Gemini across all metrics. GPT-4.1-mini is the 4th-best model across all metrics.
- We see that scaling laws hold and that the larger models perform better than the smaller ones.
- The drop in performance of the smaller models is quite concerning. Phi-4, which has 14b params and is supposed to be the best in class for its size, is 15 points or more worse off on all metrics in comparison to flagship models.
- Unlike other popular benchmarks, this seemingly simple task is far from saturated. Gemini has a JudgeLLM accuracy of 0.821, would you trust a doctor who doesn’t recognize every 5th medical term that they use 🙃?
Future Work
- Run similar experiments to benchmark embedding models.
- Run similar experiments to benchmark models on other domains.
- Invert the definition prediction task to see if models can generate definitions given a word.
- Evaluate domain-specific/adapted LLMs on the same task.
Conclusions
Industries like Healthcare/Medicine are highly regulated and demand high precision because of the high stakes involved. An error rate of 20% in understanding key medical jargon highlights how these models are far from being reliable.
Concerns around privacy and cost might force companies to deploy open-sourced, smaller models, but their performance is drastically worse than the premier models.
Definition learning and recognition should become a staple phase of model training and should be one of the first evals that a model goes through.
One of the things about model pre-training algorithms that’s bugged me for a long time is the “let’s just throw everything at it” approach. A more structured approach is to first teach the model the meanings of words, followed by grammatical rules. This approach might be more efficient and fruitful. I hope this blog makes the AI community think a bit more about these aspects of model training.
Acknowledgements
This work was inspired by my collaboration on a tangentially related project with the AI team at Healiom. Special thanks to Ash Damle for seeding this experiment in my mind.
Cite as
1
2
3
4
5
6
7
@article{pramodith2025medical_definition_understanding,
author = Pramodith B,
title = {Do LLMs know the meaning of Medical Terms?},
journal = {pramodith.github.io},
year = {2025},
url = {https://pramodith.github.io/posts/2025-05-12-medical-definition-understanding/}
}