Speculative Decoding Tutorial
A tutorial on implementing speculative decoding, an inference optimization technique for LLMs, using PyTorch and Hugging Face Transformers.
Speculative Decoding Tutorial
Speculative decoding is a technique used to speed up the generation of tokens from a generative deep learning model. The main idea is to leverage a smaller model often referred to as the “draft model” to generate K draft tokens auto-regressively. The target model i.e. the model that we actually want to use for generation then scores these K tokens in parallel, and we accept or reject them based on some criteria.
Speculative decoding guarantees that the final output matches the one that would have been obtained by using the target model alone when we use greedy decoding. When we use sampling-based decoding strategies like top-k or nucleus sampling, speculative decoding (often referred to as speculative sampling in this context) guarantees that the probability distribution over outputs matches that of the target model exactly. This means that the statistical properties and quality of outputs are identical to sampling from the target model alone, but individual samples for a given random seed may differ. For more info on speculative sampling read this paper.
This blog/notebook shows how to implement speculative decoding in the greedy decoding setting using PyTorch and the Hugging Face Transformers library without using a pre-built function for speculative decoding. The notebook version of the blog is available here.
Let’s install the necessary libraries and set up the environment for speculative decoding.
1
2
#!uv add transformers accelerate hf_xet
!pip3 install -qqq transformers accelerate hf_xet
1
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
Draft and Target Models
Let’s load the draft and target models. In this blog we will use SmolLM2-360M as our draft model and SmolLM2-1.7B as our target model. One of the key requirements for speculative decoding is that the draft model should:
- Be significantly smaller than the target model to ensure faster token generation.
- Uses the same tokenizer as the target model. This ensures that there’s a 1-1 mapping between the tokens generated by the draft model and those scored by the target model.
Note: There have been a few algorithms that reconcile the differences in tokenizers between the draft and target models, but they are out of scope for this blog. For more on this checkout Universal Assisted Generation: Faster Decoding with Any Assistant Model.
1
2
3
4
5
draft_model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM2-360M-Instruct", device_map="auto")
draft_tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-360M-Instruct")
target_model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct", device_map="auto")
target_tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
Let’s create a couple of prompts to test speculative decoding. Both the prompts guarantee that a decent number of tokens need to be generated and can also easily be verified for correctness. The knowledge intensive nature of the prompts also that the draft model is likely to make mistakes, allowing us to see how speculative decoding handles rejections.
1
2
3
4
prompts = [
"The 50 states of the USA in alphabetical order are: ",
"The countries of South America in alphabetical order are: ",
]
In this tutorial we’ll use the draft model to generate 8 tokens. After every 8 tokens generated by the draft model, the target model will score them in parallel and accept or reject them based.
We’ll also just focus on greedy decoding for now i.e. the draft model will always pick the token with the highest probability at each step.
1
2
3
4
5
6
7
8
9
10
11
import torch
import platform
target_model.eval()
num_draft_tokens = 8
greedy_gen = GenerationConfig(num_beams=1, do_sample=False, max_new_tokens=num_draft_tokens, use_cache=True)
if torch.cuda.is_available():
device_type = "cuda"
elif platform.system() == "Darwin" and getattr(torch.backends, "mps", None) is not None and torch.backends.mps.is_available():
device_type = "mps"
else:
device_type = "cpu"
Let’s sample a prompt and encode them using draft and target model tokenizers. We’ll compare the encoded tokens to ensure that both tokenizers produce the same tokens for the same prompt as a way to verify that both models use the same tokenizer.
1
2
3
4
5
import random
prompt = random.sample(prompts, 1)[0]
inputs = target_tokenizer.encode(prompt, return_tensors="pt").to(device_type)
draft_inputs = draft_tokenizer.encode(prompt, return_tensors="pt").to(device_type)
assert torch.equal(inputs, draft_inputs)
Let’s run the prompt through both the draft and target models to see what the outputs from both models look like. We can observe that both the models have slightly different outputs. Remember that our implementation of speculative decoding, should ensure that the final output matches that of the target model exactly.
1
2
3
4
5
6
7
draft_output_tokens = draft_model.generate(inputs=inputs, generation_config=GenerationConfig(num_beams=1, do_sample=False, max_new_tokens=256, use_cache=True))[0]
draft_tokenizer.decode(draft_output_tokens)
target_output_tokens = target_model.generate(inputs=inputs, generation_config=GenerationConfig(num_beams=1, do_sample=False, max_new_tokens=256, use_cache=True))[0]
target_tokenizer.decode(target_output_tokens)
assert not torch.equal(draft_output_tokens,target_output_tokens)
To gauge potential speedups from speculative decoding, let’s use %%timeit to see how long it takes the draft and target models to produce a response for our prompt.
1
2
%%timeit
target_output_tokens = target_model.generate(inputs=inputs, generation_config=GenerationConfig(num_beams=1, do_sample=False, max_new_tokens=256, use_cache=True))[0]
1
2
%%timeit
draft_output_tokens = draft_model.generate(inputs=inputs, generation_config=GenerationConfig(num_beams=1, do_sample=False, max_new_tokens=256, use_cache=True))[0]
Implementing Speculative Decoding
In this tutorial we’ll assume a batch size of 1 for simplicity.
Here are the steps to the algorithm:
- Generate K draft tokens using the draft model.
- Run a single forward pass of the target model to obtain the probability scores of tokens at each of the K positions.
- Check if the token corresponding to the highest probability score assigned by the target model at position i (1 <= i <= K) matches the draft token at position i.
- Identify the first position j where the draft token does not match the target model’s highest probability token. Steps 3 and 4. check if there’s a discrepancy between the greedy outputs of the draft and target models.
- After the previous step we know that:
- Draft tokens 1 to j-1 would have been generated by the target model as well, so we can accept these tokens.
- Despite draft token j being wrong, we know what the correct token should’ve been (i.e. the token with the highest probability score assigned by the target model at position j). So we can prepare out next input sequence by appending the accepted tokens (1 to j-1) and the correct token at position j to our existing input sequence.
- If all K tokens were accepted, we can simply append all K tokens to our input sequence and also append the next token predicted by the target model at position K+1.
- Repeat the process until the desired sequence length is reached or a stop token is generated.
Why can’t we accept more than one token from the target model?
Let’s assume that our prompt is Jack and Jill and the draft model generates 3 draft tokens: went down a.
- Target model tokens with highest prob scores:
- Position 1:
went(matches draft) - Position 2:
up(does not match draftdown) - Position 3:
to(does not match drafta)
- Position 1:
- We accept the token
upat position 2 because the prefixJack and Jill wentwould have been generated by the target model as well and auto-regressive generation for the next token depends only on the prefix. - However, we cannot accept the token
toat position 3 because the prefix at this position when the model was used for scoring would have beenJack and Jill went downsince the input to the target model comes from the draft model. So the input/prefix to the target model at position 3 is different from what it would have been if we had generated tokens auto-regressively using the target model alone.
No forward pass through the target model gets wasted
If no draft tokens were accepeted, we still know what the correct token should be at position 1 after the forward pass through the target model. So we can append this token to our input sequence and move forward. We already discussed the case for when j or all K tokens are accepted and how we can always append one token from the target model after each iteration. This means that regardless of how many draft tokens were accepted, we always make progress by appending at least one token from the target model after each iteration. This ensures that no forward pass through the target model is wasted.
Putting it all together
Here’s the complete implementation of speculative decoding based on the steps discussed above. This implementation assumes a batch size of 1 and uses greedy decoding for the draft model.
1
2
3
4
5
def prune_cache(cache, num_tokens_to_keep):
for i in range(len(cache.layers)):
cache.layers[i].keys = cache.layers[i].keys[:, :, :num_tokens_to_keep]
cache.layers[i].values = cache.layers[i].values[:, :, :num_tokens_to_keep]
return cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
def speculative_decoding(prompt, max_new_tokens, gen_config) -> torch.LongTensor:
# Initialize all variables
do_stop = False
inputs = target_tokenizer.encode(prompt, return_tensors="pt").to(device_type)
original_prompt_len = inputs.shape[1]
target_past_key_values = None
draft_past_key_values = None
while not do_stop:
# Generate draft tokens
prompt_len = inputs.shape[1]
draft_output = draft_model.generate(
inputs=inputs,
past_key_values=draft_past_key_values,
generation_config=gen_config,
return_dict_in_generate=True
)
draft_tokens = draft_output.sequences[:, prompt_len: ]
# Create inputs for target model
if target_past_key_values:
# when using caching only the inputs corresponding to unseen tokens are passed
validation_inputs = torch.cat([inputs[:, -1].unsqueeze(1), draft_tokens], dim=1)
else:
validation_inputs = torch.cat([inputs, draft_tokens], dim=1)
with torch.no_grad():
target_output = target_model(
validation_inputs,
use_cache=True,
return_dict=True,
past_key_values=target_past_key_values
)
# extract logits for tokens that need to be validated
if target_past_key_values:
logits = target_output.logits
else:
logits = target_output.logits[:, prompt_len-1:]
probs = torch.nn.functional.softmax(logits, dim=-1)
model_predicted_tokens = torch.argmax(probs, dim=-1)
# Compare draft tokens with target model predicted tokens and find the first mismatch
if not torch.all(model_predicted_tokens[:, :-1] == draft_tokens):
mismatch = torch.argwhere(model_predicted_tokens[:, :-1] != draft_tokens)[0][1]
mismatched_token = model_predicted_tokens[0, mismatch]
matched_draft_tokens = draft_tokens[:, :mismatch]
inputs = torch.cat([inputs, matched_draft_tokens, mismatched_token.unsqueeze(0).unsqueeze(0)], dim=1)
else:
inputs = torch.cat([inputs, draft_tokens, model_predicted_tokens[0, -1].unsqueeze(0).unsqueeze(0)], dim=1)
# Prune past key values caches until the last matched token
cache_length = inputs.shape[1] - 1
target_past_key_values = prune_cache(target_output.past_key_values, cache_length)
draft_past_key_values = prune_cache(draft_output.past_key_values, cache_length)
# Check stopping criteria
if target_tokenizer.eos_token_id in inputs or (max_new_tokens - (inputs.shape[1] - original_prompt_len)) < 0:
do_stop=True
final_answer = inputs[0, : min(torch.argwhere(inputs[0]==target_tokenizer.eos_token_id)+1, max_new_tokens)]
return final_answer
That blob of code might seem a bit initimidating so let’s break it down into parts.
1
2
3
4
5
do_stop = False
inputs = target_tokenizer.encode(prompt, return_tensors="pt").to(device_type)
original_prompt_len = inputs.shape[1]
target_past_key_values = None
draft_past_key_values = None
The criteria for stopping the generation loop is either reaching the maximum number of new tokens or generating a stop token. We convert our prompt into tokens (we can use the target model tokenizer since both models use the same tokenizer). We’ll take note of the length of the original prompt to help us determine when we’ve generated enough new tokens. We also initialize a couple of variables to store the past key values from both models.
The past key values will be used for correctly populating the KV-cache.
1
2
3
4
5
6
7
8
9
10
while not do_stop:
# Generate draft tokens
prompt_len = inputs.shape[1]
draft_output = draft_model.generate(
inputs=inputs,
past_key_values=draft_past_key_values,
generation_config=gen_config,
return_dict_in_generate=True
)
draft_tokens = draft_output.sequences[:, prompt_len: ]
In this blob we generate the K draft tokens. Since we only need the newly generated tokens, we slice the output sequences to only keep the newly generated draft tokens.
KV-Cache and Input Preparation for the target model
1
2
3
4
5
6
# Create inputs for target model
if target_past_key_values:
# when using caching only the inputs corresponding to unseen tokens are passed
validation_inputs = torch.cat([inputs[:, -1].unsqueeze(1), draft_tokens], dim=1)
else:
validation_inputs = torch.cat([inputs, draft_tokens], dim=1)
Here we prepare the inputs for the target model. When using the .forward() method with caching enabled, we only need to pass the inputs that haven’t been seen by the model before.
In the very first iteration, this’d be the original prompt + the K draft tokens since our KV-cache is empty. In subsequent iterations, the unseen tokens i.e. tokens without their KV values populated in the cache would be the very last token of our input i.e. the token corresponding to either the mismatched draft token or the final token predicted by the target model in the previous iteration if all the draft tokens in the previous iteration were accepted.
Remember that in auto-regressive generation we only need the KV-values of all previous tokens to generate the next token. This means that the token that’s been generated most recently hasn’t gone through a forward pass of the model yet to populate it’s KV-cache.
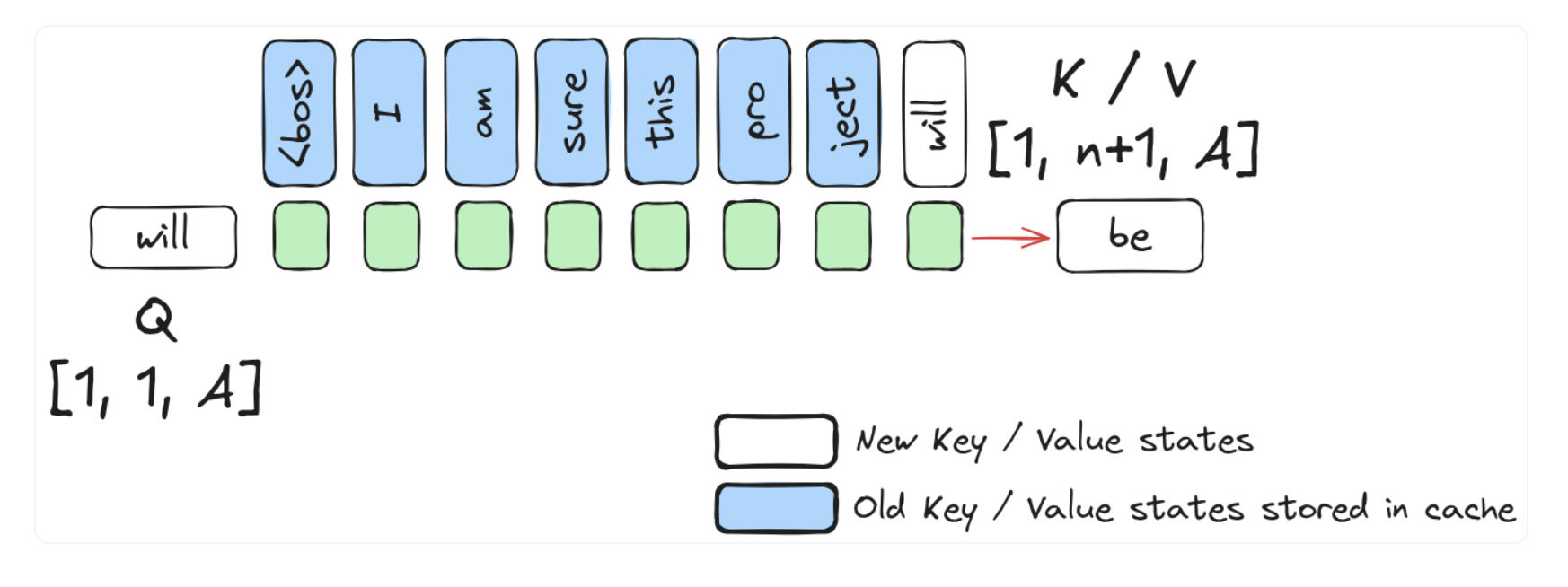
Notice how in the image above, the token be isn’t in the KV-cache yet since it was just generated. Image source
1
2
3
4
5
6
7
8
9
10
11
12
13
14
with torch.no_grad():
target_output = target_model(
validation_inputs,
use_cache=True,
return_dict=True,
past_key_values=target_past_key_values
)
# extract logits for tokens that need to be validated
if target_past_key_values:
logits = target_output.logits
else:
logits = target_output.logits[:, prompt_len-1:]
probs = torch.nn.functional.softmax(logits, dim=-1)
model_predicted_tokens = torch.argmax(probs, dim=-1)
Now that we’ve prepared our inputs for the target model, we can run a single forward pass to score all the draft tokens in parallel. We extract the logits corresponding to the draft tokens only since those are the ones we need to validate.
We need to index the logits from prompt_len-1 since the logit score at position prompt_len-1 corresponds to the score of the first draft token.
We also extract the predictions of the target model by taking the argmax of the probabilities at each position.
1
2
3
4
5
6
7
8
# Compare draft tokens with target model predicted tokens and find the first mismatch
if not torch.all(model_predicted_tokens[:, :-1] == draft_tokens):
mismatch = torch.argwhere(model_predicted_tokens[:, :-1] != draft_tokens)[0][1]
mismatched_token = model_predicted_tokens[0, mismatch]
# Prepare next input sequence
inputs = torch.cat([inputs, draft_tokens[:, :mismatch], mismatched_token.unsqueeze(0).unsqueeze(0)], dim=1)
else:
inputs = torch.cat([inputs, draft_tokens, model_predicted_tokens[0, -1].unsqueeze(0).unsqueeze(0)], dim=1)
Now that we have the predicted draft tokens and the target model’s predicted tokens, we can compare them to find the first mismatch. If there’s a mismatch, we prepare our next input sequence by appending the accepted draft tokens and the correct token from the target model. If all draft tokens were accepted, we append all draft tokens and also the next token predicted by the target model.
KV-Cache Pruning
1
2
3
4
5
def prune_cache(cache, num_tokens_to_keep):
for i in range(len(cache.layers)):
cache.layers[i].keys = cache.layers[i].keys[:, :, :num_tokens_to_keep]
cache.layers[i].values = cache.layers[i].values[:, :, :num_tokens_to_keep]
return cache
1
2
3
4
# Prune past key values caches until the last matched token
cache_length = inputs.shape[1] - 1
target_past_key_values = prune_cache(target_output.past_key_values, cache_length)
draft_past_key_values = prune_cache(draft_output.past_key_values, cache_length)
The KV-cache of the draft model and the target model after each forward pass/generation would contain the KV-values of both the accepted draft tokens and the rejected tokens. However, in the next iteration we only need the KV-tensors until the last accepted token. The size of inputs by this step is going to be original_prompt_len + num_accepted_draft_tokens + 1 since we append one token from the target model after the accepted draft tokens. So we prune the KV-cache to only keep the first inputs.shape[1] - 1 tokens.
1
2
3
# Check stopping criteria
if target_tokenizer.eos_token_id in inputs or (max_new_tokens - (inputs.shape[1] - original_prompt_len)) < 0:
do_stop=True
Finally we check if we’ve generated enough new tokens or if we’ve generated a stop token to determine if we should stop the generation loop.
Conclusion
Yay! We’ve reached the end of our implementation. Now let’s verify a couple of things:
- We’ll use
%%timeitto compare the time taken by speculative decoding vs the target model alone to generate the same number of tokens. - We’ll compare the outputs from speculative decoding and the target model alone to ensure that they match exactly.
1
2
%%timeit
speculative_decoding(prompt, 256, greedy_gen)
We can see that our implementation of speculative decoding is faster than using the target model alone to generate the same number of tokens and is slower than using the draft model alone.
We can also confirm that the outputs from speculative decoding and the target model alone match exactly, verifying the correctness of our implementation.
1
2
3
4
5
speculative_output_tokens = speculative_decoding(prompt, 256, greedy_gen)
assert torch.equal(
target_output_tokens,
speculative_decoding_output_tokens
)
References
- Accelerating Large Language Model Decoding with Speculative Sampling
- https://github.com/romsto/Speculative-Decoding